We introduce the task of generative panoramic image stitching, which
aims to synthesize seamless panoramas that are faithful to the content
of multiple reference images containing parallax effects and strong
variations in lighting, camera capture settings, or style. In this
challenging setting, traditional image stitching pipelines fail,
producing outputs with ghosting and other artifacts. While recent
generative models are capable of outpainting content consistent with
multiple reference images, they fail when tasked with synthesizing
large, coherent regions of a panorama. To address these limitations, we
propose a method that fine-tunes a diffusion-based inpainting model to
preserve a scene's content and layout based on multiple reference
images. Once fine-tuned, the model outpaints a full panorama from a
single reference image, producing a seamless and visually coherent
result that faithfully integrates content from all reference images.
Our approach significantly outperforms baselines for this task in terms
of image quality and the consistency of image structure and scene
layout when evaluated on captured datasets.
Overview
We introduce a generative method for panoramic image stitching
from multiple casually captured reference images that exhibit
strong parallax, lighting variation, and style differences. Our
approach fine-tunes an inpainting diffusion model to match the
content and layout of the reference images. After fine-tuning,
we outpaint one reference image (e.g., the leftmost reference
view shown here) to create a seamless panorama that
incorporates information from the other views. Unlike prior
methods such as RealFill, which produces artifacts when
outpainting large scene regions (red boxes), our method more
accurately preserves scene structure and spatial composition.
Method
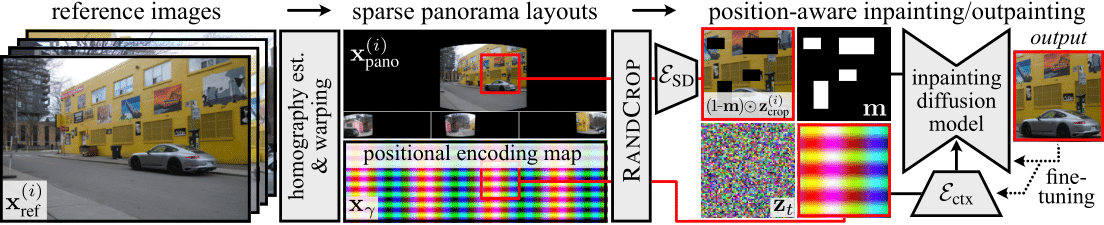
Method overview. Given a set of reference images
$\{\mathbf{x}_{\text{ref}}^{(i)}\}_{i=1}^{N}$, we generate sparse panorama layouts
$\{\mathbf{x}_{\text{ref}}^{(i)}\}_{i=1}^{N}$ by detecting
features, estimating homographies, and
warping each reference image to its location in a sparse panorama
containing only that image. We then fine-tune a pre-trained inpainting
diffusion model for a position-aware inpainting/outpainting task.
During training, random crops are taken from the sparse panoramas and a
positional encoding map $\mathbf{x}_{\gamma}$. Each panorama crop is processed
using an encoder $\mathcal{E}_{\text{SD}}$, and we we multiply the resulting latent
image $\mathbf{z}^{(i)}_\text{crop}$ with a random binary mask
$(1-\mathbf{m})$. We process the crop of $\mathbf{x}_{\gamma}$ with an encoder
$\mathcal{E}_{\text{ctx}}$ and use the result to condition the diffusion model. The
other inputs -- the masked version of $\mathbf{z}_\text{crop}^{(i)}$,
the mask $\mathbf{m}$, and the noisy latent image $\mathbf{z}_t$ -- are
concatenated together and passed as input to the model. After
fine-tuning, we generate seamless panoramas by outpainting one of the
initial sparse panoramas.}
Gallery
BibTex
@article{tuli2025generative,
title={Generative Panoramic Image Stitching},
author={Tuli, Mathieu and Kamali, Kaveh and Lindell, David B.},
booktitle={arxiv},
year={2025}
}